Chaturbate
Chaturbate is a live adult webcam streaming site. It allows people to broadcast themselves through a webcam and make money … Read More
Chat with Cam Girls & Watch Sex Shows
Chaturbate is a live adult webcam streaming site. It allows people to broadcast themselves through a webcam and make money … Read More

Fetish Live Cam is a webcam site that features live, interactive fetish performances. They usually involve one or more performers … Read More

Cheap Live Girls is a website offering live webcam performances by models, typically featuring nudity and sexual activity. It offers … Read More
Fetish Plus is a website that offers many different types of fetish and BDSM cams available online. Depending on the … Read More
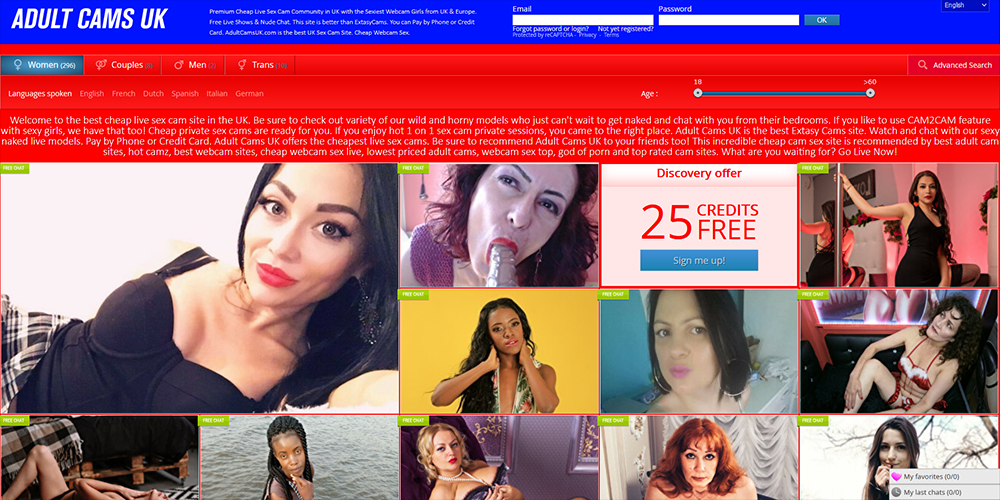
If you are looking for an exciting way to meet new people and have some adult fun, then you should … Read More
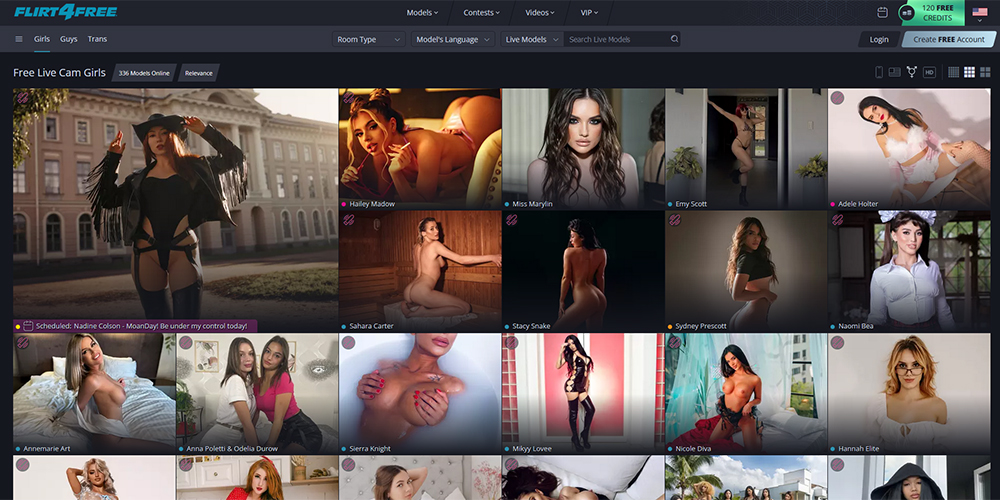
Flirt4Free is an adult webcam platform that has been around since 1996. It offers a variety of features, including high-definition … Read More
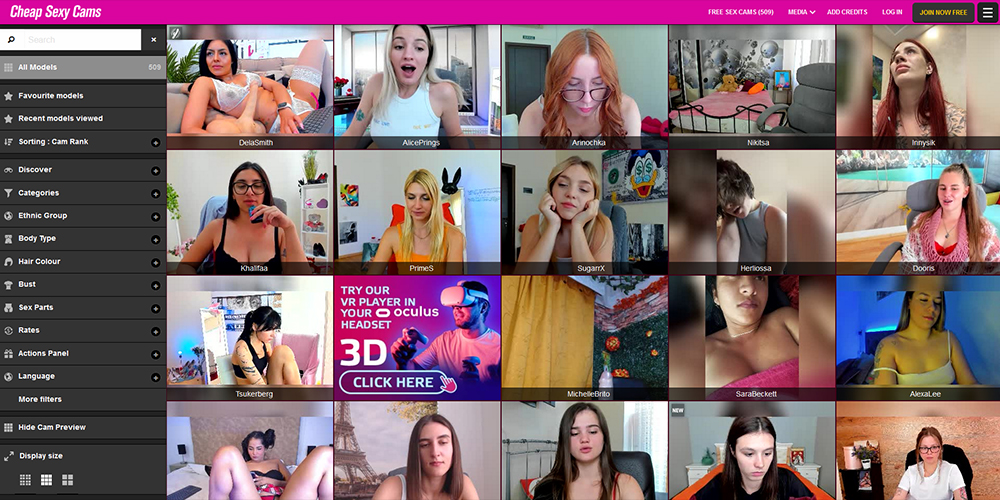
Cheap Sexy Cams is an adult video chat site where users can communicate with models via webcam. Models on the … Read More

UK Cam Sex is the best adult site to chat with hot and horny UK cam models. This site offers … Read More
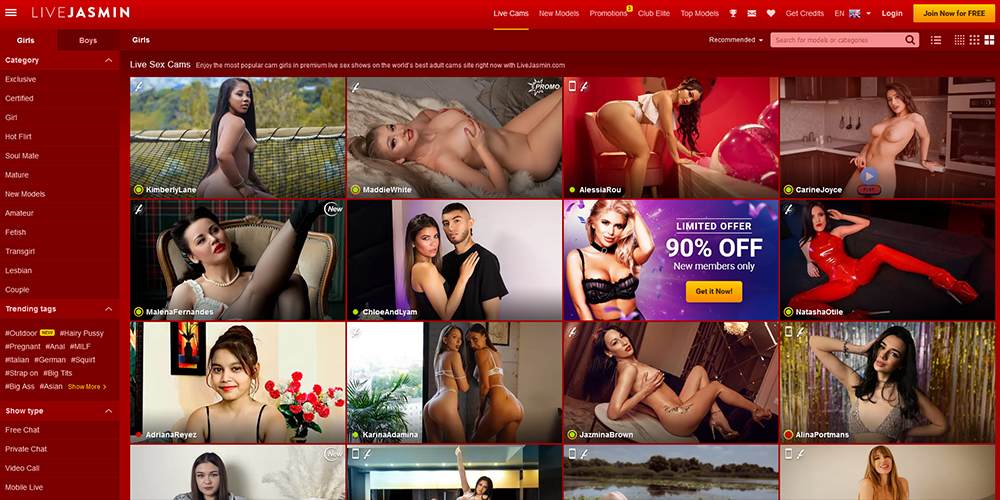
Live Jasmin is an adult webcam streaming website that was launched in 2001. It is one of the oldest and … Read More

SkyPrivate is a Skype plugin that allows users to pay per minute for private webcam sessions with models offering adult … Read More
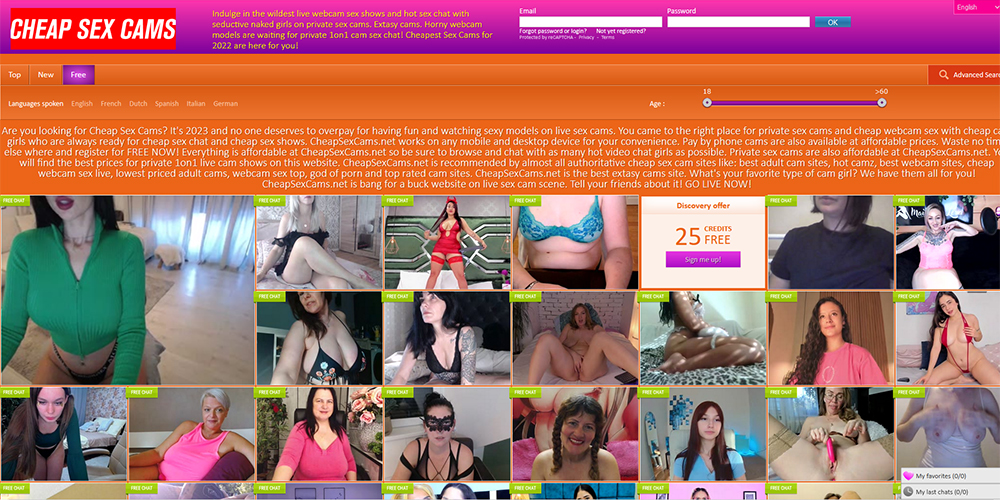
If you’re looking for a safe, welcoming, entertaining live adult entertainment experience, then you should try out the Cheap Sex … Read More

Sex Cams 2GO is the best website for live adult cams, which uses the Pay By Phone payment method. Sex … Read More
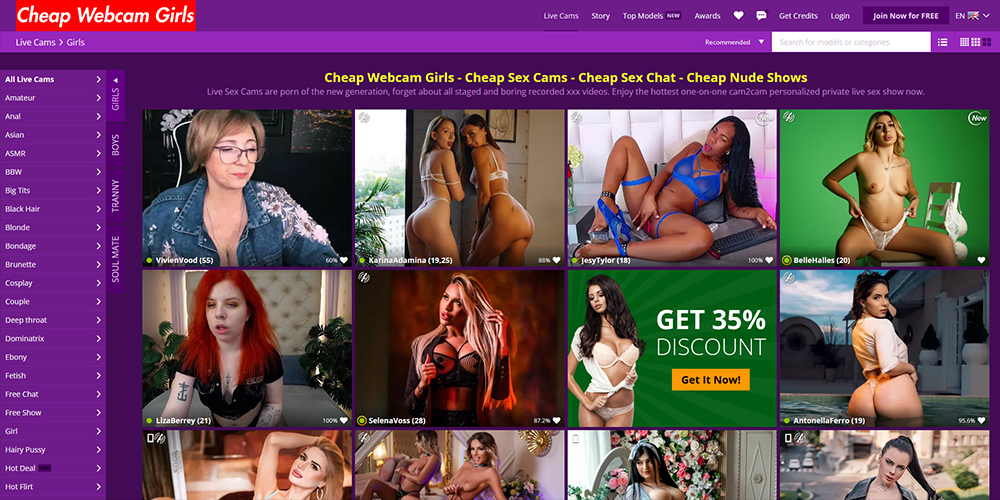
Cheap Webcam Girls is an adult-oriented live-streaming cam site that provides users with access to live webcam shows featuring models, … Read More